Abstract

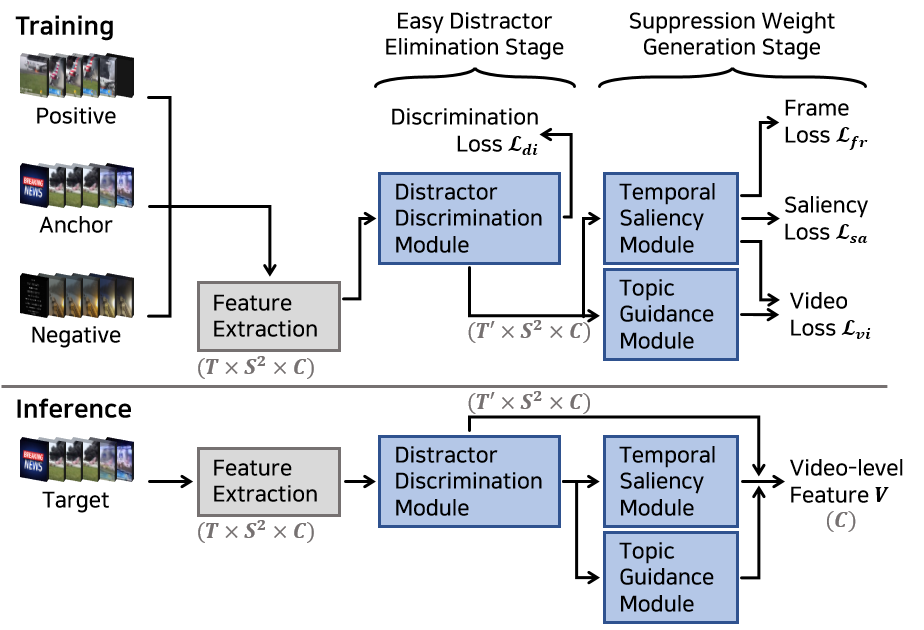
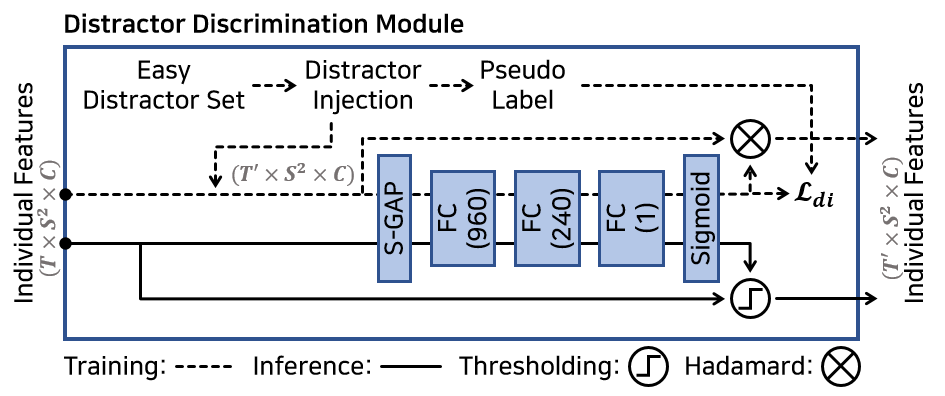
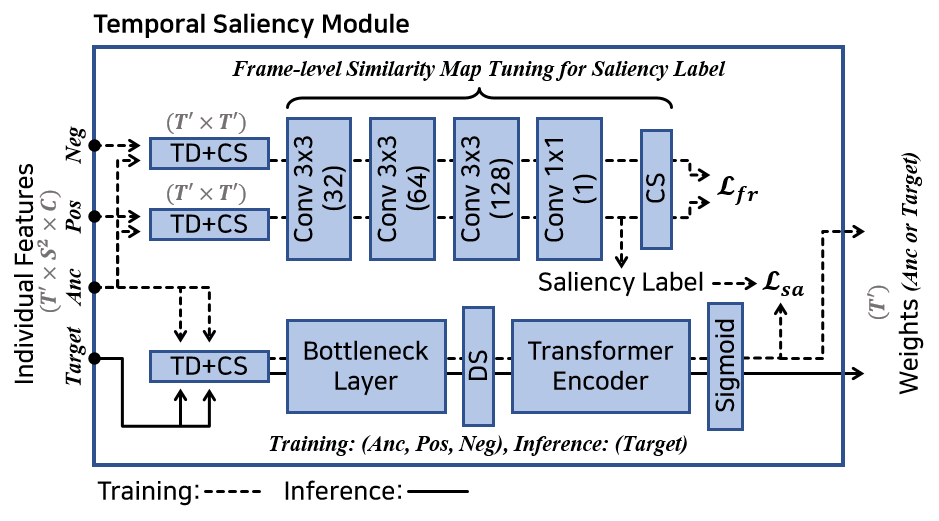
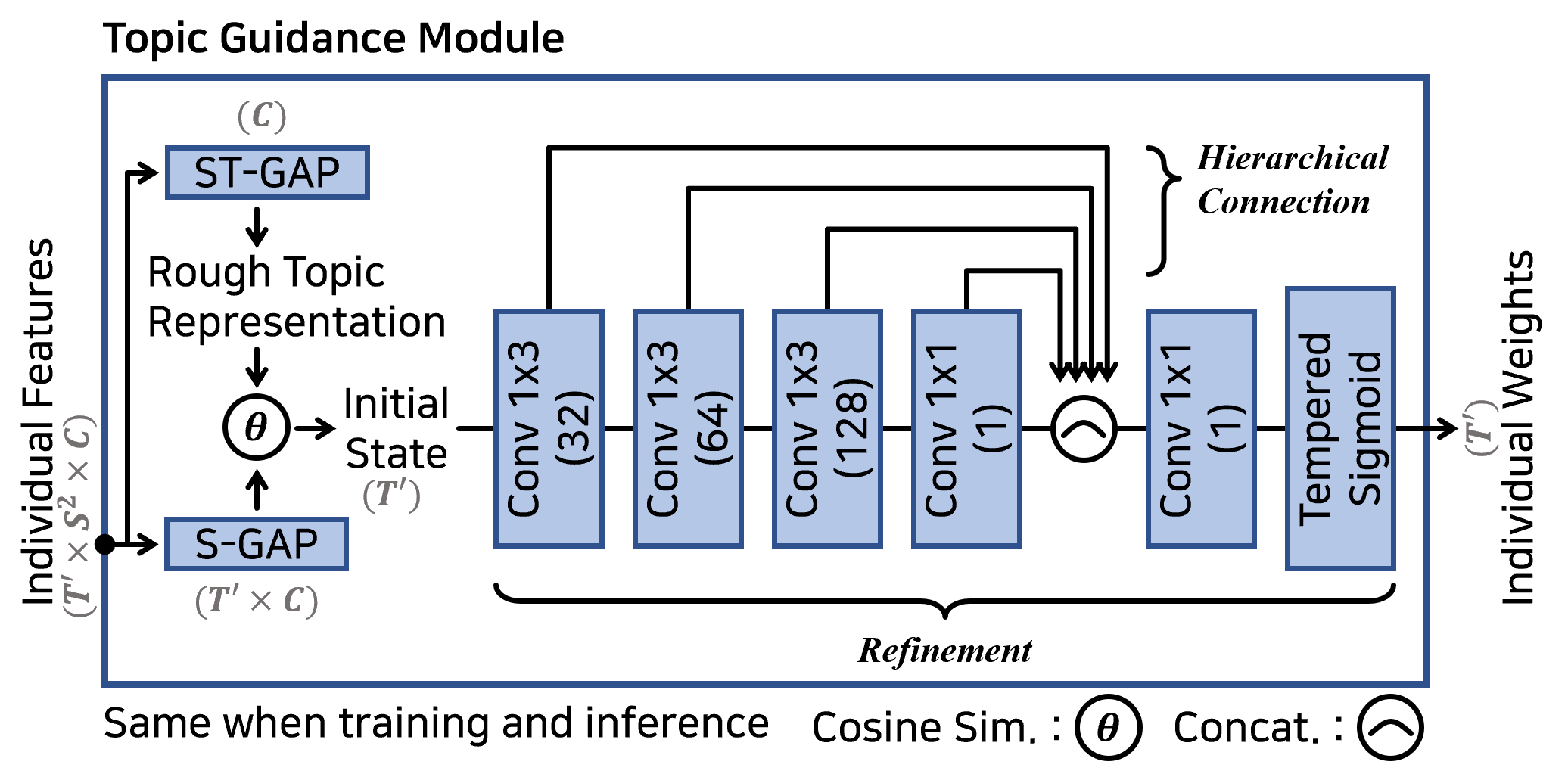
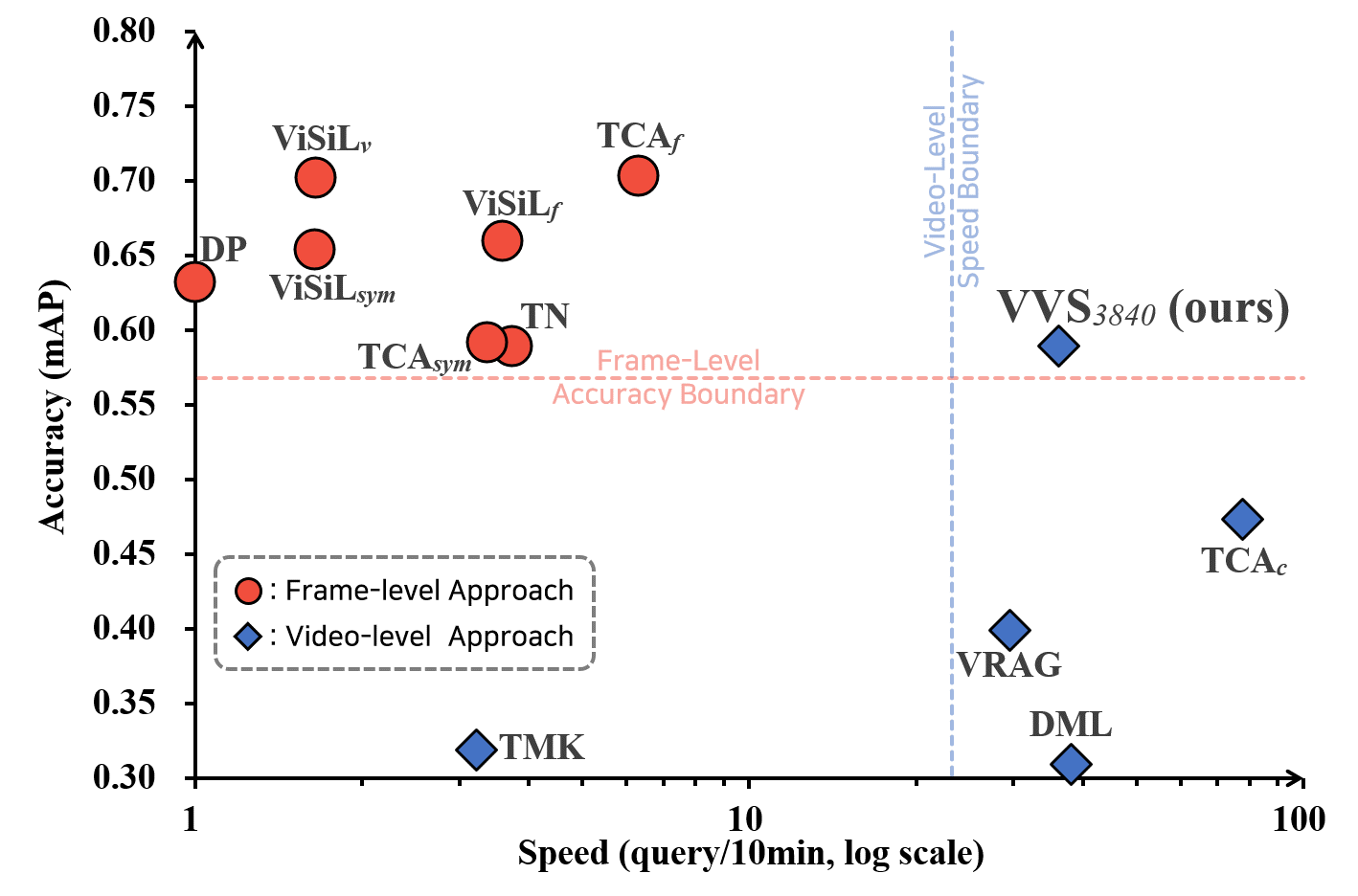
In content-based video retrieval (CBVR), dealing with large-scale collections, efficiency is as important as accuracy; thus, several video-level feature-based studies have actively been conducted. Nevertheless, owing to the severe difficulty of embedding a lengthy and untrimmed video into a single feature, these studies have been insufficient for accurate retrieval compared to frame-level feature-based studies. In this paper, we show that appropriate suppression of irrelevant frames can provide insight into the current obstacles of the video-level approaches. Furthermore, we propose a Video-to-Video Suppression network (VVS) as a solution. VVS is an end-to-end framework that consists of an easy distractor elimination stage to identify which frames to remove and a suppression weight generation stage to determine the extent to suppress the remaining frames. This structure is intended to effectively describe an untrimmed video with varying content and meaningless information. Its efficacy is proved via extensive experiments, and we show that our approach is not only state-of-the-art in video-level approaches but also has a fast inference time despite possessing retrieval capabilities close to those of frame-level approaches.